728x90
문장의 유사도를 구하기 위해서 다양한 유사도 기법을 사용한다.
그 중 코사인 유사도에 대해 알아보자.
코사인 유사도
코사인 유사도는 두 벡터의 코사인 각도로 구할 수 있다.
두 벡터의 각도가 0°인 경우는 1
90°인 경우는 0
180°로 반대의 방향을 가지면 -1
코사인 유사도는 -1과 1사이의 값을 갖게 되며 1에 가까울수록 유사도가 높다고 말할 수 있다.

아래 식은 코사인 유사도를 식으로 표현한 것이다.
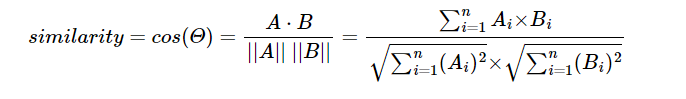
활용
코사인 유사도 구하기
# overview열에 대한 TF-IDF 행렬 구하기
tfidf = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf.fit_transform(data['overview'])
print('TF-IDF 행렬의 크기(shape) :',tfidf_matrix.shape)
#TF-IDF 행렬의 크기(shape) : (20000, 47487)
# 20000개의 영화와 47487개의 단어가 사용됨
# 20,000개의 문서 벡터에 대한 상호 간 코사인 유사도
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
print('코사인 유사도 연산 결과 :',cosine_sim.shape)
#코사인 유사도 연산 결과 : (20000, 20000)영화 다크 나이트 라이즈와 overview가 유사한 영화들을 찾기
# title_to_index: 영화의 타이틀을 key, 영화의 인덱스를 value로 하는 딕셔너리
title = 'The Dark Knight Rises'
# 선택한 영화의 타이틀로부터 해당 영화의 인덱스를 받아온다.
idx = title_to_index[title]
# 해당 영화와 모든 영화와의 유사도를 가져온다.
sim_scores = list(enumerate(cosine_sim[idx]))
# 유사도에 따라 영화들을 정렬한다.
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# 가장 유사한 10개의 영화를 받아온다.
# 자기 자신은 제외
sim_scores = sim_scores[1:11]
# 가장 유사한 10개의 영화의 인덱스를 얻는다.
movie_indices = [idx[0] for idx in sim_scores]
# 가장 유사한 10개의 영화의 제목을 리턴한다.
print(data['title'].iloc[movie_indices])
출처: https://wikidocs.net/book/2155
딥 러닝을 이용한 자연어 처리 입문
많은 분들의 피드백으로 수년간 보완된 입문자를 위한 딥 러닝 자연어 처리 교재 E-book입니다. 오프라인 출판물 기준으로 코드 포함 **약 1,000 페이지 이상의 분량*…
wikidocs.net
728x90
'AI > 자연어 처리' 카테고리의 다른 글
| [자연어처리] 간단한 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq) (0) | 2023.02.17 |
|---|---|
| 서브워드 토크나이저(1) - BPE (0) | 2023.02.15 |
| [자연어처리] Word2Vec, Skip-gram (0) | 2023.02.13 |